



Das Bitcoin Mining bildet gemeinsam mit den Full Nodes das Rückgrad von Bitcoin. Ohne Miner keine neuen Blöcke, ohne Full Nodes keine Blockchain. Kurz zusammengefasst ist die Aufgabe eines Miners das Finden eines Blockes, der den Anforderungen gemäß der aktuellen Difficulty entspricht. Miner fassen neue, unbestätigte Transaktionen in Blöcken zusammen. Gemeinsam mit einem Zeitstempel, einer Prüfsumme des letzten Blocks und einer als Nonce bekannten Zählvariable bilden sie eine neue Prüfsumme. Diese ist auch als Hash bekannt. Kann dieser Hash eine durch die Difficulty definierte Anzahl von Nullen vorweisen hat der Miner einen gültigen Block gefunden. Der Block wird mit dem Node-Netzwerk geteilt.
Wer in diese Thematik mehr eindringen möchte sei auf unsere Academy oder auf den Podcast zum Thema Proof of Work verwiesen. Wir möchten heute etwas genauer auf die Zählvariable oder Nonce schauen. Wie wir das machen, soll, gemäß dem Motto “Be your own Analyst”, genauer erklärt werden.
Nonce: Fingerabdruck für ASIC-Boost oder Miner-Typ?
Auf den ersten Blick könnte man denken, dass die Nonce eine einfache Zählvariable sei. Wenn jedoch alle Miner von einer Nonce von eins an durchzählen, wird immer der Miner gewinnen, der am besten mit den Full Nodes verbunden ist. Miner mit einer schlechteren Internet-Verbindung hätten keine Chance. Außerdem wäre die kombinierte Hash Rate von mehreren Minern, die allesamt dieselben Blöcke berechnen nicht viel wert, wenn alle mit denselben Nonces arbeiten würden.
Es gibt also Gründe, warum man bezüglich der Nonces als Miner etwas nachdenken sollte. Doch es kommt noch mehr: Im letzten Jahr berichteten BitMex Research und CoinMetrics über Anomalien in der Nonce-Verteilung. So konnte man feststellen, dass zwischen 2017 und 2019 kaum Blöcke mit bestimmten Nonces gefunden wurden. Sie beziehen sich dabei auf einen Tweet von PlanB:
Soweit zur Entwicklung bis Anfang 2019. BitMEX und ursprünglich auch CoinMetrics hatten als These, dass diese Pattern durch das Mining mit sogenanntem ASIC-Boost herrühren würden. Wie sich alte Hasen erinnern war ASIC-Boost einer der Motivationen für die Einführung von Segregated Witness. Im Newsletter von Anfang April 2020 korrigiert CoinMetrics die Einschätzung und vermutet, dass diese Anomalien durch die Bitmain-Miningserie S9 gekommen wäre. Diese ASIC-Miner-Serie kommt nun zu einem Ende und wird durch die S17er nach und nach abgelöst.
Die Frage, die wir untersuchen möchten, ist nun: Kann man Muster wie die obigen noch sehen? Und gibt es auf dem Weg andere interessante Findings? Schauen wir uns dazu die Blöcke des letzten Monats an.
Auf Blockjagd: Wie kommen wir zu interessanten Blockdaten?
Wollen wir die Blöcke zwischen 31. März und 29. April genauer anschauen, muss uns eines klar sein: Wir betrachten über 4.000 Blöcke. Mit einem einzigen API-Call wie in alten Ausgaben dieser Reihe ist es leider nicht getan.Wir müssen zwar nicht an die rohen Blöcke selbst ran, aber die Metadaten für einzelne Blöcke herunterladen.
Aber es gibt Lösungen, die nicht in einem Herunterladen der gesamten Blockchain bestehen. Die API von BTC.com kann einem hier unschätzbare Dienste erweisen. Mit einem API-Call der Form ([Blockhöhe] durch Zahl ersetzen)
https://chain.api.btc.com/v3/block/[Blockhöhe]lassen sich so verschiedene Informationen über einen einzelnen Block erhalten. Mit etwas mehr codetechnischen Aufwand und, der Einfachheit halber, einer for-Schleife, können wir über einen bestimmten Zeitraum die Block-Infos speichern. Dabei gehen wir wie folgt vor. Im ersten Schritt laden wir die verwendeten Bibliotheken (tidyverse und jsonlite) und bereiten vor, welche Blöcke wir alles laden wollen:
library(tidyverse)
library(jsonlite)
today <-Sys.Date()
dataset_btc <- NULL
stop_size_btc_raw <- fromJSON('https://chain.api.btc.com/v3/block/latest')
stop_size_btc <- as.numeric(stop_size_btc_raw$data$height)
start_size_btc <- stop_size_btc-(31*144)-1
range_btc<-start_size_btc:stop_size_btcDie etwas obskuren 31*144 ergeben sich aus einer einfachen Rechnung: Pro Tag finden die Bitcoin–Miner im Mittel 144 Blöcke, so dass man pro Monat rund auf 31*144 Blöcke kommt.
Auf der Basis können wir nun die für uns interessierten Daten in einer Tabelle ablegen.Wie oben angekündigt machen wir dies mit einer for-Schleife, welche über einen API-Call die Informationen für jeden Block in Erfahrung bringt.
Wir machen, um die API nicht zu überfordern und keine Fehler auszulösen, eine halbe Sekunde Pause und laufen die Schleife dann erneut durch. Danach werden die so gesammelten Daten in einer csv-Datei gespeichert:
for(i in 1:(31*144+2)) {
tryCatch({
print(paste0("Blöcke: BTC bei ",range_btc[i]))
block_btc_raw <- paste0('https://chain.api.btc.com/v3/block/',range_btc[i])
block_btc <- fromJSON(block_btc_raw)
row_btc <- NULL
row_btc$height <- range_btc[i]
row_btc$size_mb <- block_btc$data$size/1024/1024
row_btc$n_tx <- block_btc$data$tx_count
row_btc$when <- as.POSIXct(block_btc$data$timestamp,origin="1970-01-01")
row_btc$nonce <- block_btc$data$nonce
row_btc$fees <- block_btc$data$reward_fees
row_btc$pool <- block_btc$data$extras[["pool_name"]]
row_btc$delta <- 0
dataset_btc <- rbind(dataset_btc, as.data.frame(row_btc))
dataset_btc$delta <- c(0,tail(dataset_btc$when, -1) -
head(dataset_btc$when, -1))
}, error = function(e) {
print("error")
})
Sys.sleep(0.5)
}
write.csv(dataset_btc,paste("BTC_",Sys.Date(),".csv",sep=""))tryCatch({...}, error = ...) ist als eine Hilfe eingebunden, damit der Code nicht durch einen Fehler sofort abbricht. Sollte es also zu Unpässlichkeiten kommen würden wir so wenigstens mit einem Teil der Daten enden. Das ist wichtig, schließlich dauert das Laufen lassen des obigen Codes mehrere Stunden. Entweder macht man dies am Heimcomputer und lässt ihn währenddessen laufen oder man ist bequem und eröffnet einen Account auf RStudio Cloud. So oder so: Zeit für nicht nur einen Kaffee.
Übrigens: Die API liefert noch deutlich mehr Block-Infos als die von uns gespeicherten. Mit fromJSON(paste0('https://chain.api.btc.com/v3/block/',[Blockhöhe])) sind noch deutlich mehr als die hier aufgeführten Daten zu finden (Wobei [Blockhöhe] durch die entsprechende Zahl zu ersetzen ist). Sie liegen in einem JSON-Format vor.
Ein datengestützter Blick aufs Bitcoin-Mining
So, der Kaffee ist getrunken, die tolle Netflix-Serie ist gebinged und an das tolle Self-Improvement-Buch, was wir unbedingt mal lesen wollten haben wir gedacht, unser obiger Code sollte also fertig sein. Und tatsächlich: Er ist es.
Zeit also, die Daten genauer anzuschauen. Wir laden die mit obigem Code erstellte csv-Datei dazu in einen folder namens „data“ und lesen die csv-Datei in eine Variable namens „daten“ ein:
library(tidyverse)
library(lubridate)
daten <- read_csv("data/BTC_2020-04-29.csv")Bevor wir uns auf die Nonces werfen betrachten wir, wie die unterschiedlichen Pools abgeschnitten haben. Dabei fokussieren wir uns auf Pools, die mehr als 100 Blöcke gefunden haben. Alle anderen fassen wir unter „Unbekannt“ zusammen. Wir speichern außerdem die „großen Pools“ in der Variable „large_pools“:
large_pools <- daten %>% group_by(pool) %>% summarise(n=n()) %>%
arrange(desc(n)) %>% mutate(pool=ifelse(n>100,pool,"Unbekannt")) %>%
group_by(pool) %>% summarise(n=sum(n)) %>% arrange(desc(n)) %>%
mutate(pool=factor(pool,levels=pool))
large_pools %>% ggplot(aes(pool,100*n/sum(n),fill=pool)) +
geom_col(show.legend = F) +
labs(x="",y="Gefundene Blöcke in Prozent") +
theme_minimal() + theme(axis.text.x = element_text(angle = 45, hjust = 1))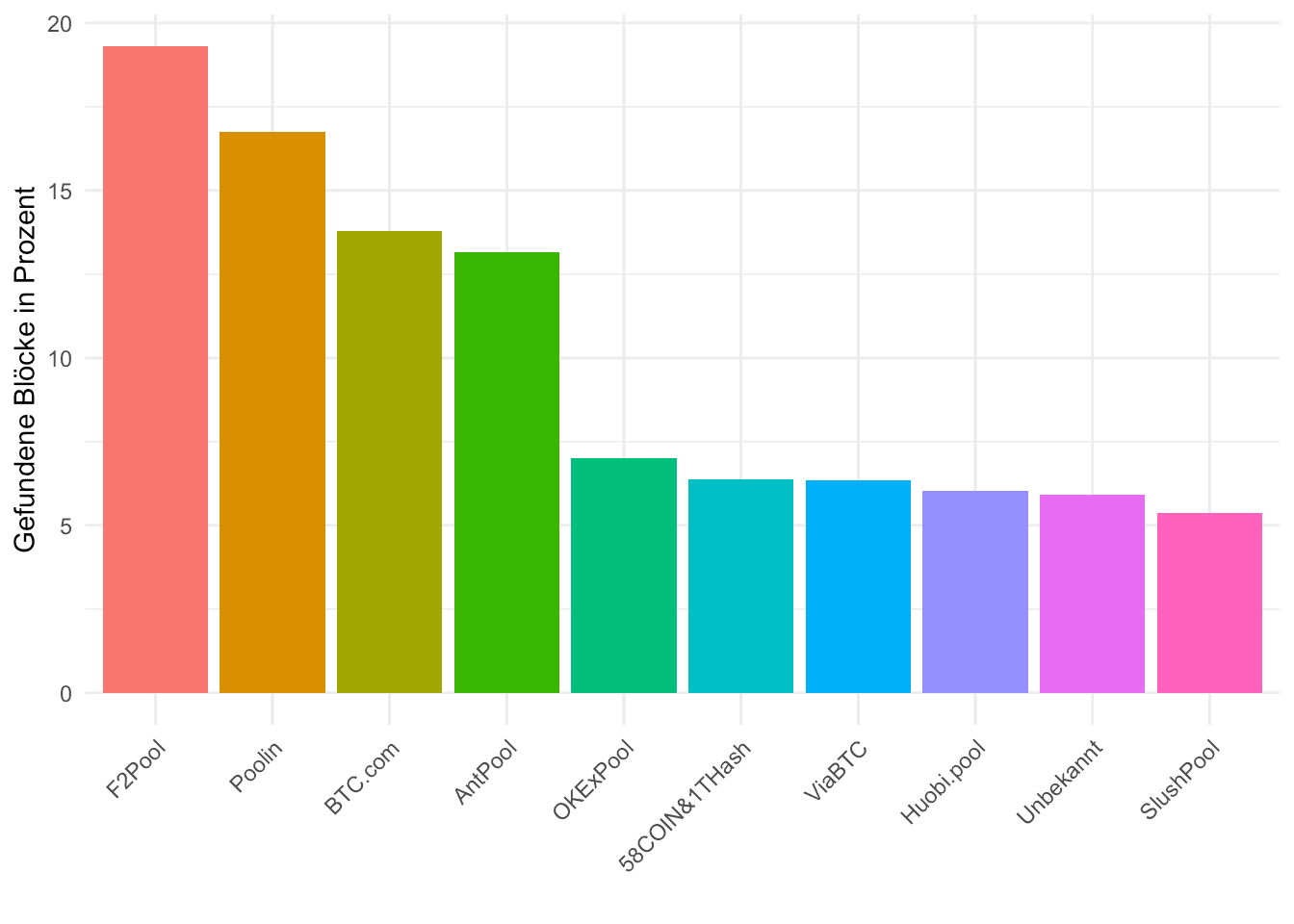
Da diese sonstigen Pools, wie wir sehen, kaum etwas von der Hash Rate ausmachen, fokussieren wir uns in erster Linie auf die größeren Pools.
Wie waren bezüglich dieser Blöcke die Nonces verteilt? Unabhängig von den Pools ist zu sehen, dass in der Bitcoin Blockchain Blöcke mit hohen Nonces weniger vorkommen als mit niedrigen:
daten %>% ggplot(aes(nonce/10^9)) +
geom_histogram(fill="#FFA838",col="#555555",bins=100) +
labs(x="Nonce / Milliarden", y="Treffer") + theme_minimal()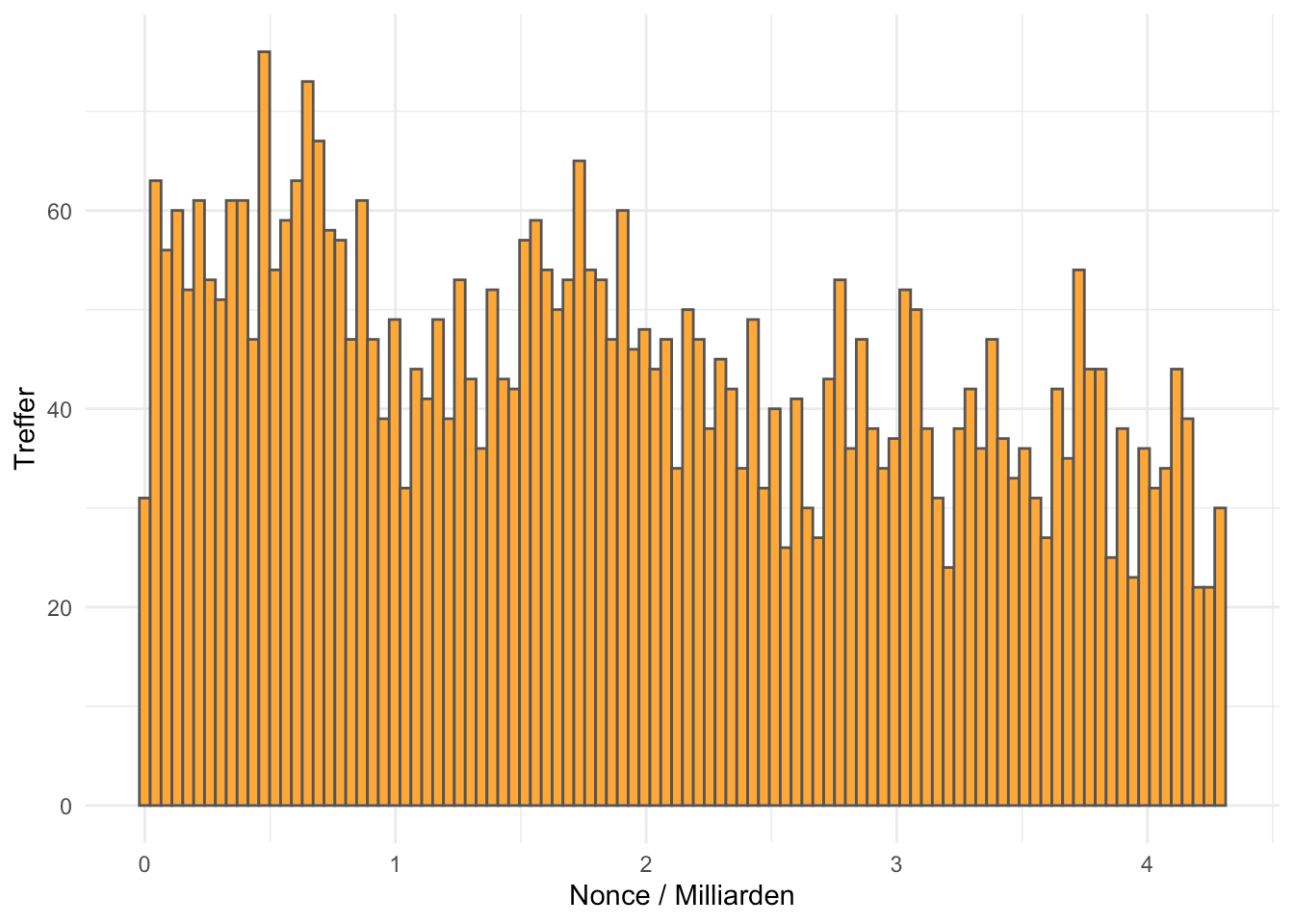
Soweit würde sich die These eines „einfachen Durchzählens“ bestätigen: Da mit einer niedrigen Nonce begonnen und jeweils nur bis zum Finden eines Blocks die Nonce variiert wird wäre ein entsprechendes Verhalten zu erwarten.
Betrachten wir jedoch unterschiedliche Pools sehen wir ebenso unterschiedliche Pattern. Wir fokussieren uns dabei auf die neun größten Pools:
`%nin%` <- Negate(`%in%`)
daten %>% filter(pool %nin% small_pools$pool) %>%
ggplot(aes(nonce/10^9,fill=factor(pool,levels =
large_pools$pool[large_pools$pool!="Unbekannt"]))) +
geom_histogram(show.legend = F,bins=100) +
facet_wrap(factor(pool,levels =
large_pools$pool[large_pools$pool!="Unbekannt"])~., scales = "free_y") +
labs(x="Nonce / Milliarden", y="Treffer") + theme_minimal()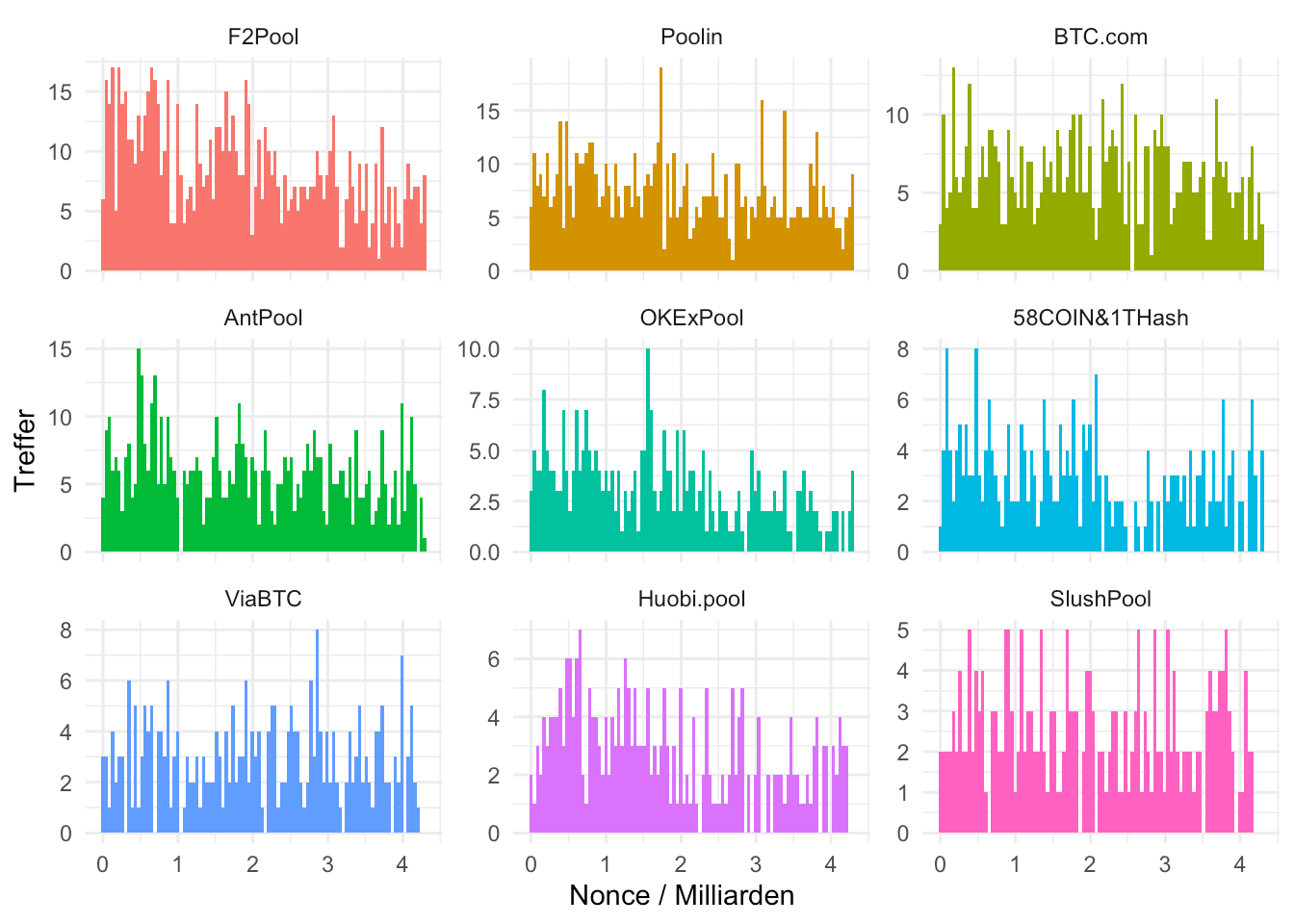
Manche Mining Pools wie F2 Pool, OKExPool und HuobiPool bestätigen den betrachteten Trend. Andere jedoch wie Poolin, BTC.com und Antpool weisen nicht ein derartiges Fallen auf.
Wir sehen jedoch auch, insbesonderer für F2Pool und AntPool noch Strukturen, die an die oben erwähnten Findings von PlanB erinnern. Wir sehen bei Nonces von rund einer Milliarde und 2,5 Milliarden starke Einbrüche. Die Bilder sind verrauschter als das von PlanB, was sich aber auch mit der Interpretation von Coinmetrics deckt: Nach und nach verschwinden S9-Miner aus den Mining-Pools von Bitcoin.
Ein Blick auf die kleineren Bitcoin Mining Pools
Nur damit wir die kleineren Pools nicht komplett unterschlagen: Wir gehen ähnlich wie vorher vor, betrachten diese kleineren Mining Pools und speichern auch diese unter einer Variable names „small_pools“ ab. Wir sehen: Selbst der größte von denen, BTC.TOP, hat nicht einmal zwei Prozent der Blöcke im April gefunden.
small_pools <- daten %>% group_by(pool) %>%
summarise(n=n()) %>% arrange(desc(n)) %>%
filter(n<100)
small_pools %>% mutate(pool=ifelse(pool=="unknown","Sonstige",pool)) %>%
mutate(pool=factor(pool,levels=pool)) %>%
ggplot(aes(pool,100*n/4466,fill=pool)) + geom_col(show.legend = F) +
labs(x="",y="Gefundene Blöcke in Prozent") + theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))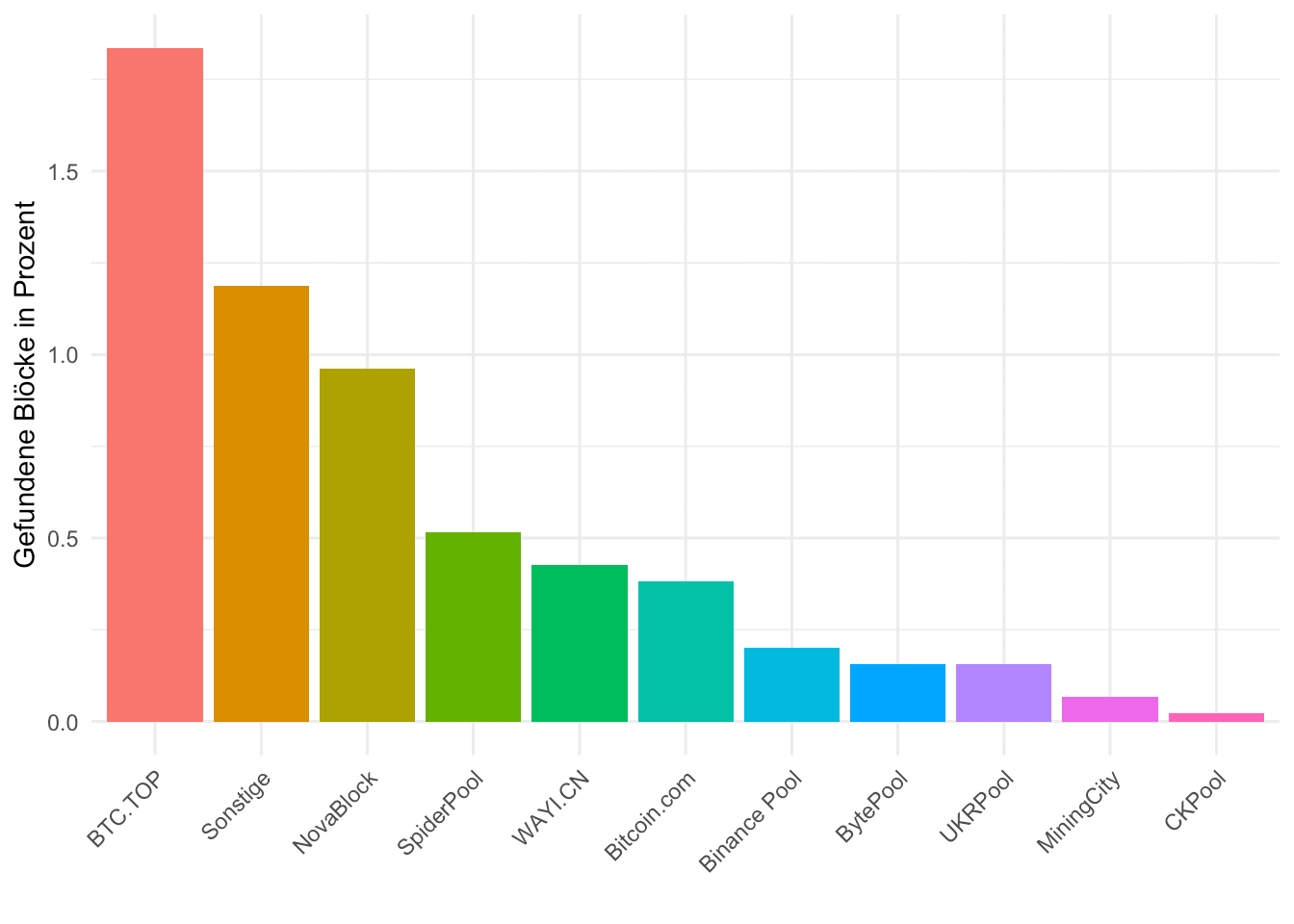
Nun wäre es interessant zu wissen, ob man bezüglich der Nonce-Verteilung etwas besonderes über diese kleinen Pools sagen könnte. Da die Statistik für die einzelnen kleinen Bitcoin-Miner sehr gering ist unterscheiden wir nicht zwischen den einzelnen Pools. Das Ergebnis ist auch aggregiert ziemlich ernüchternd:
daten %>% filter(pool %in% small_pools$pool) %>% ggplot(aes(nonce/10^9)) +
geom_histogram(show.legend = F,bins=100) +
labs(x="Nonce / Milliarden", y="Treffer") +
theme_minimal()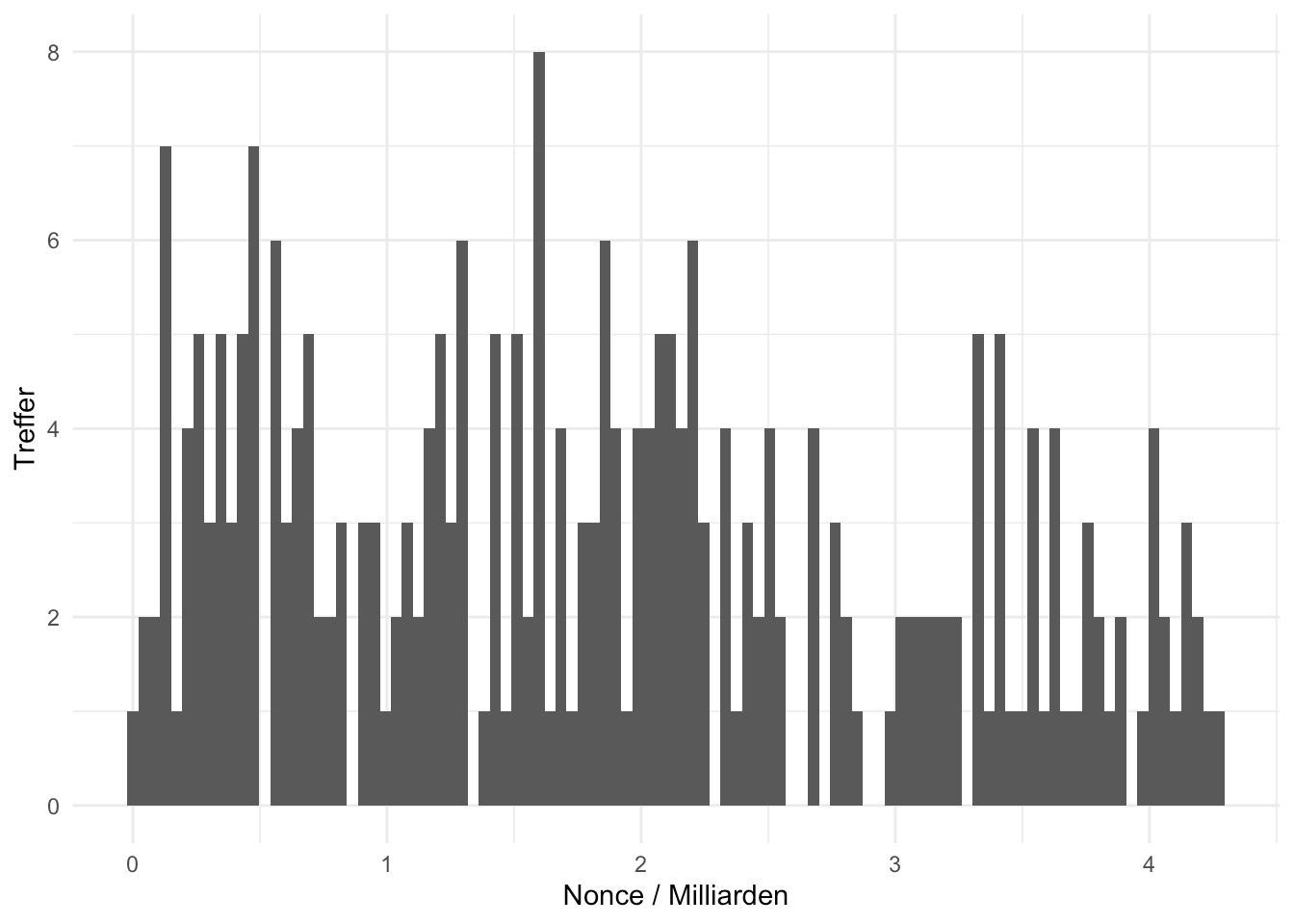
Mit etwas Phantasie lassen sich hier noch Artefakte von obigem Verhalten entdecken, aber wirklich weit sind diese nicht. Es scheint so zu sein, dass Antpool und vor allem F2pool noch einige S9-Bestände haben. Das jedenfalls wäre, basierend auf dieser Analyse und der Interpretation von Coinmetrics, eine passende Schlussfolgerung.
Erst der Anfang der Reise
Wir haben uns eine Menge an Daten über Bitcoin heruntergeladen – aber nur auf die Nonce und die Pools geschaut. Natürlich kann man noch deutlich mehr mit diesen Daten machen. Gibt es zwischen der Transaktionsanzahl in einem Block und der Blockzeit einen Zusammenhang?
daten %>% mutate(n_tx=round(log(n_tx)/log(10),0)) %>%
ggplot(aes(delta,fill=as.character(n_tx))) +
geom_histogram(bins=40) +
facet_grid(as.character(n_tx)~.,scales = "free_y") +
labs(x="Blockzeit / s", y= "Blöcke",fill="Log(Transaktionen)") +
theme_minimal()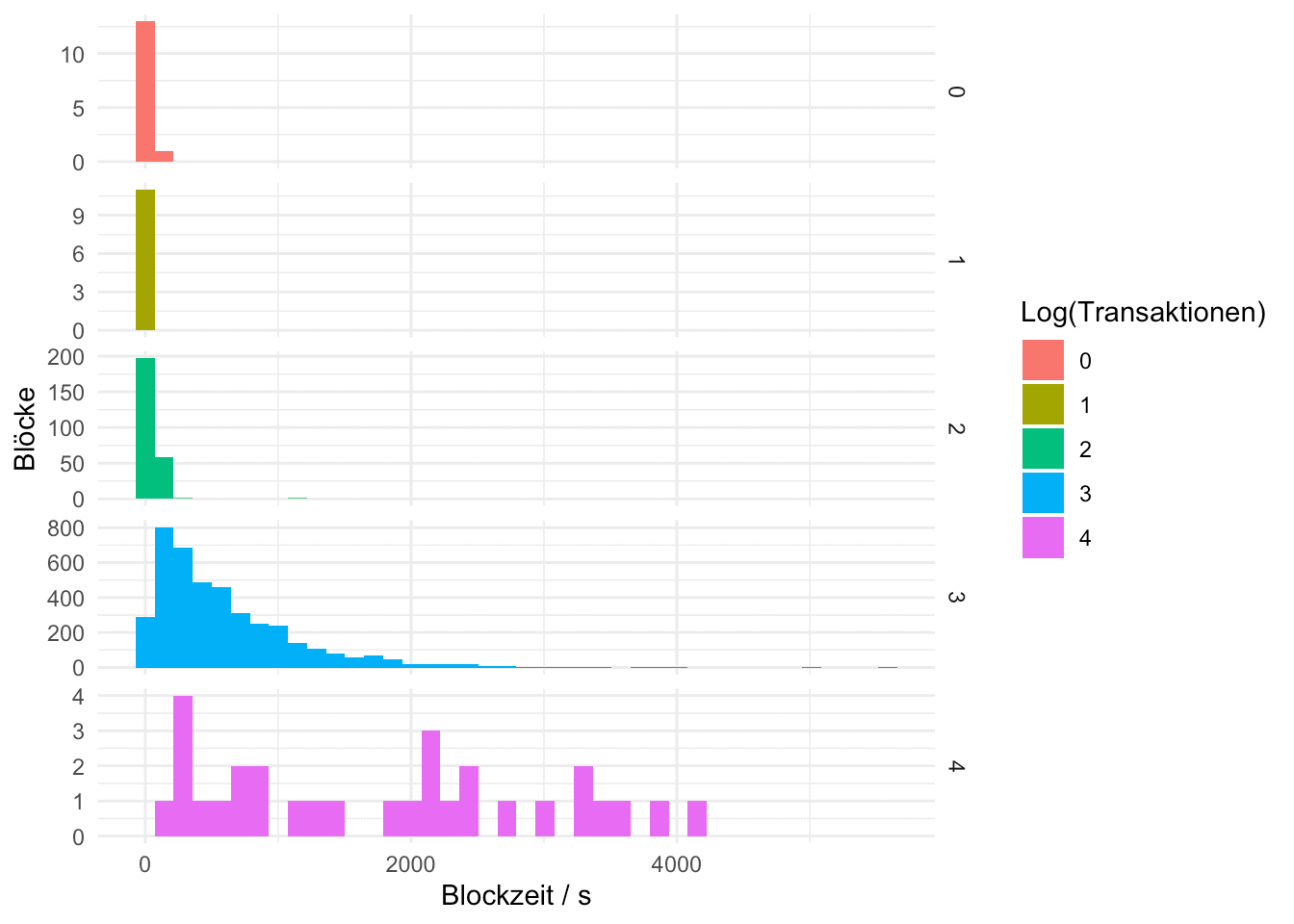
Ein wenig könnte man darüber diskutieren. In obiger Abbildung haben wir dargestellt, wie lang man ungefähr auf einen Block warten musste. Wir unterscheiden dabei Blöcke mit weniger als zehn, weniger als hundert, weniger als tausend, weniger als zehntausend Transaktionen und Blöcke mit noch mehr Transaktionen. Wir sehen, dass Blöcke mit vielen Transaktionen eher dazu neigen, etwas auf sich warten lassen – zumindest basierend auf dieser sicherlich nicht riesigen Statistik.
Das wird weniger daran liegen, dass größere Blöcke bei Bitcoin eine höhere Nonce benötigen, sondern daran, dass die Block-Zusammenstellung und gegebenenfalls Propagation längere Zeit braucht.
Das nur als ein weiteres Beispiel, was man neben Betrachten der Hash-Rate-Verteilung oder der Nonces anfangen kann. Frei nach dem Motto „Be your own Analyst“ könnt ihr nun übernehmen.



